Tesla 주가가 이렇게 많이 올랐는데 Transformer를 모른다?
Tesla 자율주행을 설명할 때 FSD만 겨우 설명하고 있다면 여기 attention 해보자.
RNN 구조에서 마지막 State의 결과만 사용하기에는 정보손실이 크기 때문에 LSTM 구조를 이용해도 여전히 Long Sequence를 학습하기 어렵다는 문제가 있다.
그래서 등장한 Transformer!!
Attention을 이용해 전체 입력 문장에서 참고해야 하는 중요한 State를 계속해서 참조하고, Positional Encoding을 이용해 순차적 데이터를 반영하는 아이디어인데..
Transformer는 bottom-up으로 이해하는 것이 쉽다.
(논문을 읽는 게 가장 빠름: Attention is all you need)
"Transformer는 encoder-decoder architecture를 따르는 attention/self-attention 기반 neural network다."
이 문장을 이해하는 걸 목표로 꼬꼬무 시작해보자.
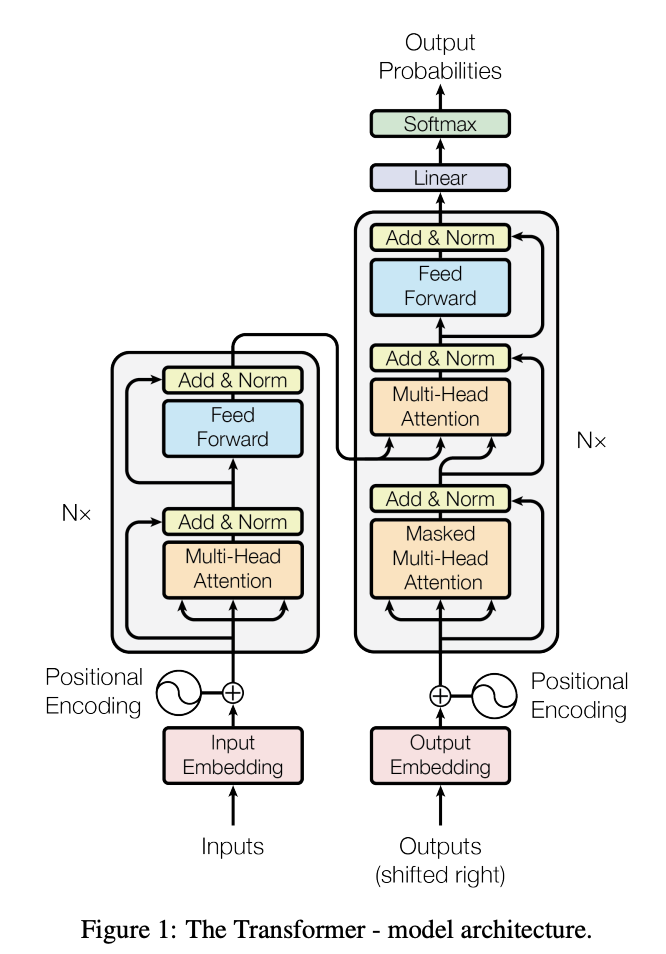
1. Attention
1.1. 정의
갑자기 attention??
여러 자극 중 특정 자극에만 집중하고 다른 자극을 배제한다는 ‘cognitive attention’의 개념을 neural network에서 사용했다고 한다.
즉, 입력 정보 중 중요한 부분은 더 중요하게 덜 중요한 부분은 덜 중요하게 보는 것을 의미한다.
다 필요없고 attention mechanism에서 이것만 기억하자!
✅ 입력 정보 중 중요한 건 더 중요하게, 덜 중요한 건 덜 중요하게 보자!
➡️ 모델의 목적인 “데이터를 입력했을 때 예측값이 잘 나오는 것”을 더 잘 달성하려는 것이 attention을 모델에 적용하는 이유다.
Attention은 구성 성분은 아니고 의미적으로 implictly 또는 구성 성분으로서 explicitly하게 neural network에서 많이 사용한다.
또한, attention은 데이터 구분 없이 여러 분야에서 많이 사용된다.
1.2. 구성
항상 query, key, value로 구성된다.
1.3. 종류
1.3.1. Explicit attention
✅ attention과 self-attention을 확실하게 구분해야 함!!!!
1) Attention: query/key/value가 같지 않은 경우
➡️ attention layer의 입력이 하나가 아닌 경우 attention이고 query/key/value 파악 필요
2) Self-attention: query/key/value가 모두 같은 경우
➡ attention layer의 입력이 하나인 경우로, query/key/value가 같은 값을 의미하는 것이 아니라 같은 source로부터 왔음을 의미
Attention 적용 방법
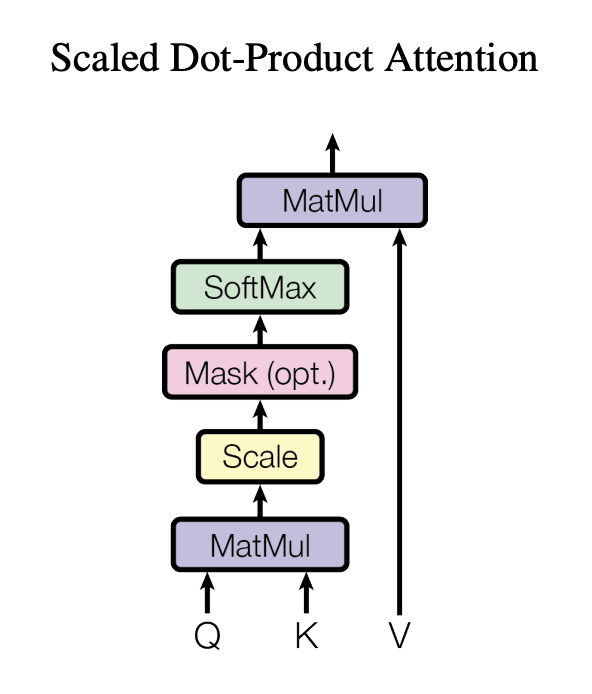
1️⃣ Query와 각각의 key들 간의 유사도(attention score)를 dot product 또는 FC layer들의 조합 등을 통해 생성
- query(목적)
- key(유사도, 비슷하면 값이 크게 됨)
- value(key와 매칭되는 값으로 목적과 관련된 것인 더 중요한 건 더 값을 크게, 덜 중요한 건 값을 작게)
➡ query는 목적과 관련이 있는데 query와 관련 있는 것들은 중요하다. 볼 수 있으므로 크게, 관련 없는 것들은 덜 중요하다고 볼 수 있으므로 작게 생성
2️⃣ Attention score에 softmax 적용
3️⃣ Softmax가 적용된 attention score를 각각의 key에 상응하는 value에 반영
➡ 각각의 유사도(중요도)를 상응하는 value에 곱해주어, value는 목적과 관련이 있는 것일 때 크게, 관련 없는 것일 때 작게 재조정
4️⃣ 유사도가 반영된 value들을 더한 결과 생성
➡ 유사도(중요도)가 반영된 하나의 embedding vector 생성
1.3.2. Implicit attention
정의: 모델 학습 시 또는 모델에 데이터 입력 시 attention의 컨셉 (중요한 것은 중요하게, 덜 중요한 것은 덜 중요하게 본다는 컨셉)을 적용한 것으로 attention을 의미하는 명시적인 layer가 존재하지 않는다.
2. Query, Key, Value
Transformer 모델에서 query는 입력 데이터를 기반으로 생성되며, 주로 attention mechanism에서 사용됩니다.
2.1. Query, Key, Value vector 생성
attention mechanism에서 query, key, value는 다음 과정에 따라 특정 매트릭스를 통해 계산된다.
1️⃣ 입력 임베딩 생성
먼저 입력 데이터를 임베딩 벡터로 변환하는데 각 단어 또는 토큰이 고차원 벡터로 변환되는 것이다.
2️⃣ Query, Key, Value 벡터 생성
입력 임베딩이 주어지면 각각의 입력 임베딩에 대해 선형 변환(가중치 행렬 곱)이 이루어지는데, 이 과정에서 Query (Q), Key (K), Value (V) 세 가지 벡터가 생성된다.
요놈들은 입력 임베딩 X에 대해 서로 다른 가중치 행렬에 의해 계산된 것이다.
\( Q = X \cdot W_Q \)
\( K = X \cdot W_K \)
\( V = X \cdot W_V \)
(where, \( W_Q \), \( W_K \), \( W_V \)는 학습 가능한 가중치 행렬)
3️⃣ 어텐션 메커니즘에서의 역할
Query는 현재 처리 중인 토큰이 다른 토큰과 얼마나 관련이 있는지를 측정하기 위한 기준이 된다.
이를 위해 Query와 Key의 내적(dot product)을 계산하여 두 토큰 간의 attention score를 구하고, 이를 통해 어떤 토큰에 주목할지를 결정한다.
2.2. Pytorch에서 Query, Key, Value vector
Transformer에서 사용되는 Query, Key, Value를 구할 때의 weight matrix는 nn.Linear를 사용하여 자동으로 생성된다.
import torch.nn as nn
class TransformerAttention(nn.Module):
def __init__(self, embed_dim):
super(TransformerAttention, self).__init__()
self.query_linear = nn.Linear(embed_dim, embed_dim)
self.key_linear = nn.Linear(embed_dim, embed_dim)
self.value_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
# Query, Key, Value 벡터 생성
query = self.query_linear(x) # Q = X * W_Q
key = self.key_linear(x) # K = X * W_K
value = self.value_linear(x) # V = X * W_V
return query, key, value
'SWE > AI' 카테고리의 다른 글
| Encoder-Decoder Architecture 사용 이유 (0) | 2024.11.13 |
|---|---|
| RNN을 쪼개보자 (1) | 2024.11.11 |
| RNN을 향한 꼬꼬무 (0) | 2024.11.10 |
| Non-linear activation function (0) | 2024.11.09 |
| 내가 가장 좋아하는 Layer는 (0) | 2024.11.08 |



